Webサービスのビジネス化(ネット未来地図)
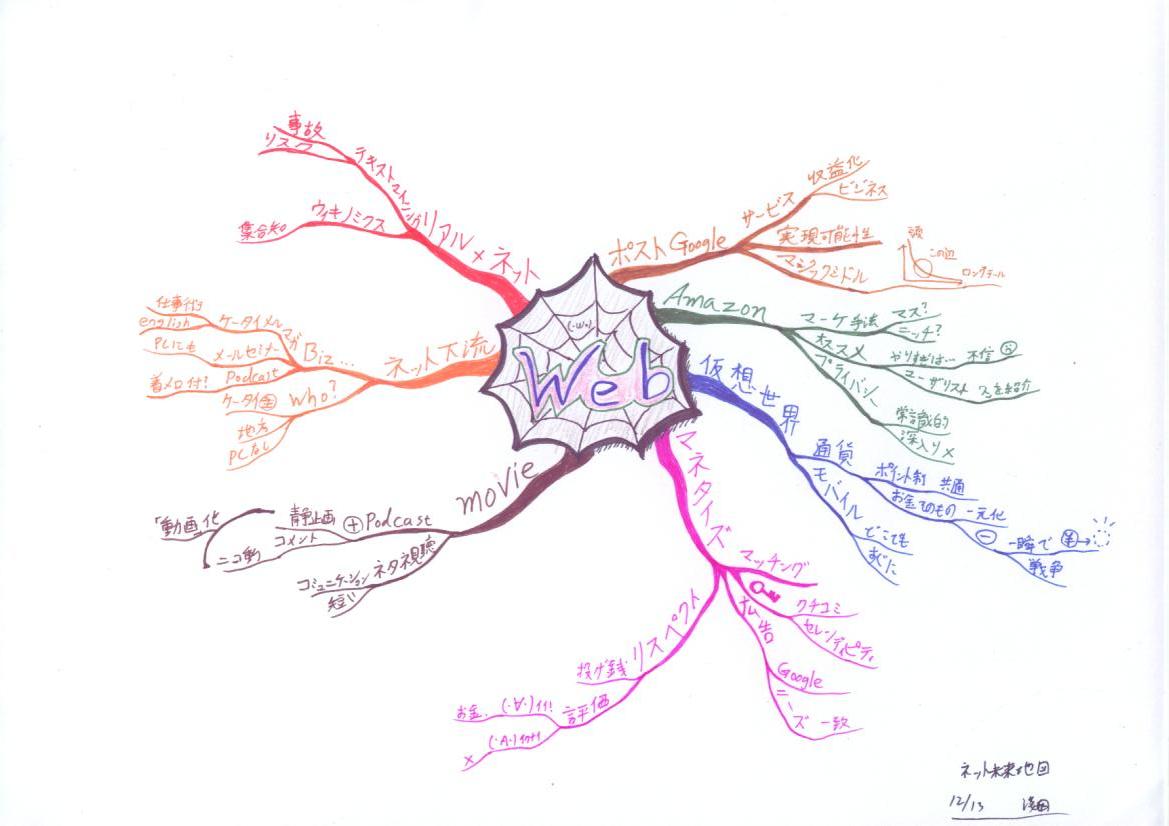
佐々木俊尚さんの「ネット未来地図」。副題は「ポスト・グーグル時代 20の論点」ということで、20のテーマに対して10ページ程度ずつ触れられています。興味のあるところから読んでもよし、頭から20個すべてを読んでもよし。
[tegaki]ネット未来 どう「ビジネス」に つながるか[/tegaki]
![]()
「収益」という観点から見た場合は、「信頼」、セレンディピティやクチコミによる「マッチング」と言ったキーワードが出てきます。この部分を掘り下げてもいいのですが…今回はちょっと趣向を変えて、「19.リアル世界」の中から一つ取り上げてみます。
※この他、「ネット下流」から派生したアイデア等もマインドマップには書いてありますので、そちらも併せてどうぞ〜。
安全レポートのテキストマイニング
このテーマ…ちょうど今、大学で研究している部分と一致する内容です。なので、本書の紹介と併せて研究紹介もしてしまおう…という狙いもあります(笑)。
本書で紹介しているのは、JALと富士通の共同研究。フライト中にトラブルなどが発生した場合、聞き取り調査などによってレポートが作成されます(FDM、あるいはインシデントレポート)。このレポートにはトラブルの原因になった情報が書かれているため、それをしっかり理解することでリスク回避・事故の防止につなぐことができます。
[tegaki]…理論上は。[/tegaki]
実際にはどうなっているかというと、「レポートが多すぎて(or 人手が足りなくて)分析が追いつかない」という状況です。
医療現場だったりすると、少なくみても「1日10〜100通 / 病院」という量のレポートが発生します。…これが全国から集まって、手作業でやったらどうなるか…。深く考えなくても予想は付くと思います(汗)。
そこで、これを機械的に扱い、一度に処理できるようにするため、「レポートのテキストマイニングを行うシステムを開発しよう」というのが大まかな趣旨です。
この際、最も重要になるのがPCにテキストを「理解」させる作業。いくら自動処理ができても、その制度が低ければ意味が無くなってしまいます。また、逆に厳密に判断させすぎると(例えば、過去の事例と照らし合わせて判断させた時、など)、応用が利かなくなり、新しいトラブル原因が出てきたときに対処できなくなります。
色々と抱える問題は多いわけで…日々、研究に頑張っているわけです(苦笑)。とは言え、こうして自分のやっている研究が(少しずつでも)認知されていくのは嬉しい事です。「東京大学の淺田が〜」とか、載るような研究成果が出るように頑張ります!
創造のタネ
Webによって何が可能になったか。ちょっと極端ですが、「人と情報が自由につながるようになった」とも言えます。上記の事故に関しても、今まで山積していた&隠されていた情報をうまく分析し、そこから得られた知識を共有しよう、という動きになりはじめています。
ただし、これはこれで問題があって、「機密事項をどう扱うか」という壁にぶち当たります。ユーザ側からしてみれば「全部素直に公開してくれ」と言いたくもなりますが、虚弱性を全部ばらしてしまうのも危険ではあります。
どこまでを公開し、どこまでを機密とするか。「安全」や「リスク」に限らず、「Web上で情報を扱う」際は常に付きまとってくる問題ですよね。
[tegaki]自分の扱っている情報は、どこまで公開できるか。[/tegaki]
たまにはこんな所を考えてみるのもいいかもしれません。

- ネット未来地図 ポスト・グーグル時代 20の論点 (文春新書 595)
- 佐々木俊尚
- ASIN: 416660595X
- [新書]
- 価格: ¥ 767
- 文藝春秋
- Amazon.co.jp で詳細を見る

編集後記
ハバネロスープが最近のお気に入りです(・ω・)